
👇复制口令打开淘宝免单奶茶和25红包👇
¥XT7U4sdjF9I¥/ HU7405
引言
神经机器翻译(NMT)在机器翻译任务中取得了显著进步。传统上,NMT模型依赖于递归神经网络或卷积神经网络来提取序列信息。这些模型存在局限性,例如无法捕捉长距离依赖关系。自注意力机制的引入为NMT带来了新的视角。自注意力允许模型关注与给定时间步相关的序列中的任何位置,从而改善了长距离依赖关系的建模。本文将深入探究自注意力在NMT中的应用,并讨论其优势和局限性。
自注意力机制
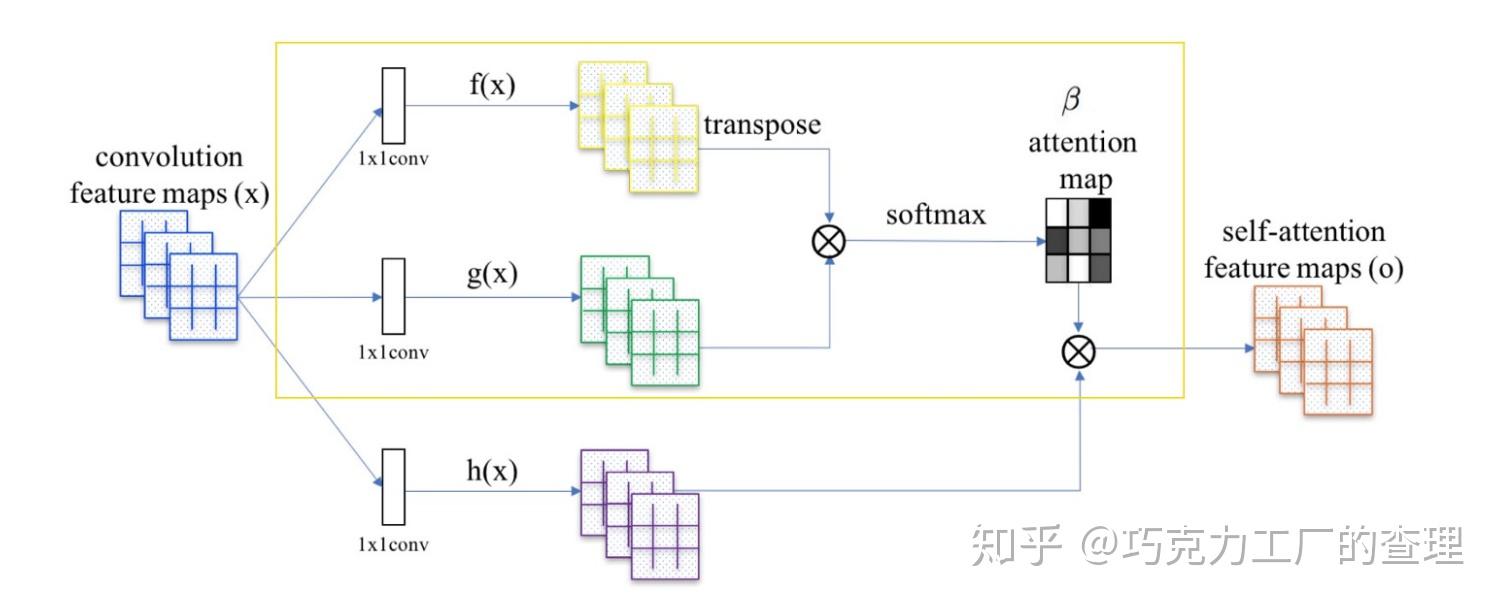
自注意力是一种神经网络模块,它计算一个序列中每个位置的加权平均值,其中权重由序列本身确定。这允许模型专注于与给定位置相关的其他位置,从而捕获长距离依赖关系。自注意力机制的数学公式如下:Q = W_Q X
K = W_K X
V = W_V XA = softmax(Q K.T)
Z = A V其中:X 是序列的表示W_Q、W_K 和 W_V 是权重矩阵Q、K 和 V 是查询、键和值矩阵A 是注意权重矩阵Z 是加权平均值
自注意力在NMT中的应用
自注意力机制已被广泛应用于NMT模型。它可以集成到编码器、解码器或两者中。
编码器中的自注意力
在编码器中,自注意力允许模型捕捉句子中不同单词之间的关系。这使得模型能够生成更丰富的语义表示,有助于提高翻译质量。
解码器中的自注意力
在解码器中,自注意力允许模型关注源句子中的特定部分,从而生成与其相关的翻译。这改进了翻译的流畅性和一致性。
同时使用自注意力
一些NMT模型同时在编码器和解码器中使用自注意力。这允许模型在源和目标句子之间建立更强的联系,从而产生更高质量的翻译。
自注意力机制的优势
捕捉长距离依赖关系: 自注意力机制可以对序列中任意两个位置计算注意力权重,这使它能够捕捉远程依赖关系。并行计算: 自注意力机制允许并行计算注意力权重,这大大提高了训练和推理速度。缓解梯度消失问题: 自注意力机制有助于缓解梯度消失问题,这是递归神经网络中常见的困难,这使得模型能够学习更长的依赖关系。
自注意力机制的局限性
计算成本高: 自注意力机制需要计算序列中所有位置之间的注意力权重,这对于长序列来说可能会非常昂贵。缺乏先验知识: 自注意力机制没有先验知识来指导注意力的分配,这可能会导致模型过度关注某些部分而忽略其他部分。容易过拟合: 自注意力机制可能容易过拟合,尤其是当训练数据集较小时。
结论
自注意力机制已成为NMT领域的一个变革性创新。通过捕捉长距离依赖关系,自注意力机制提高了翻译质量,并使模型能够生成更流畅、更一致的翻译。自注意力机制也存在一些局限性,例如计算成本高和容易过拟合。未来的研究将集中于解决这些局限性,并进一步提高自注意力机制在NMT中的应用。
相关文章
