
👇复制口令打开淘宝免单奶茶和25红包👇
¥XT7U4sdjF9I¥/ HU7405
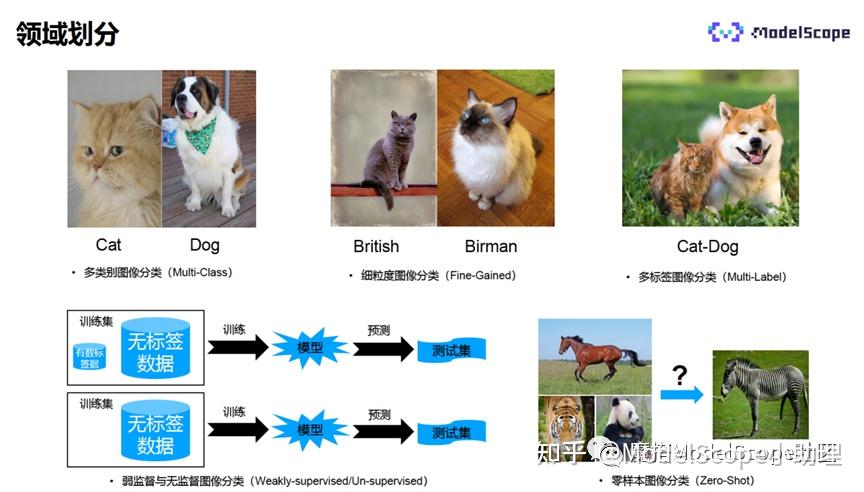
图像分类是一项计算机视觉任务,涉及识别图像中包含的对象或场景。它在许多应用中都有用处,例如:
- 医疗诊断
- 自动驾驶汽车
- 社交媒体图像分类
- 产品分类
为了执行图像分类,我们需要训练一个机器学习模型,该模型可以识别图像中的模式。TensorFlow 是一个流行的开源机器学习库,非常适合用于训练图像分类模型。
使用 TensorFlow 训练图像分类模型
以下步骤介绍了如何使用 TensorFlow 训练图像分类模型:
- 收集数据集:我们需要收集一个图像数据集,该数据集包含我们想要识别的对象或场景的图像。该数据集应包含具有各种角度、照明和背景的图像,以确保模型泛化良好。
- 准备数据:一旦我们收集了数据集,我们就需要对其进行预处理,以使其适合用于训练模型。这包括调整图像大小、归一化像素值以及将数据分成训练集和测试集。
- 选择模型:TensorFlow 提供了多种用于图像分类的神经网络模型,例如 VGGNet、ResNet 和 Inception。我们可以根据数据集的大小和复杂性选择最合适的模型。
- 定义损失函数:损失函数用于测量模型的预测值和真实标签之间的差异。在图像分类中,交叉熵损失函数通常用于多类别分类问题。
- 定义优化器:优化器用于最小化损失函数并调整模型参数。常用的优化器包括 Adam 和 RMSprop。
- 训练模型:使用定义的损失函数和优化器,我们可以训练模型。训练过程涉及将训练数据馈送到模型中并调整模型的参数,以尽量减少损失函数。
- 评估模型:训练完成后,我们需要评估模型的性能。这通常通过使用测试集来计算模型的准确性、召回率和 F1 分数等指标来完成。
- 部署模型:如果模型在测试集上表现良好,我们可以将其部署到实际应用中。这可能涉及将模型集成到 Web 应用程序、移动应用程序或其他计算平台中。
示例代码
以下示例代码展示了如何使用 TensorFlow 训练一个基本的图像分类模型:
import tensorflow as tf准备数据 (x_train, y_train), (x_test, y_test) = tf.keras.datasets.mnist.load_data()归一化数据 x_train = x_train.astype('float32') / 255 x_test = x_test.astype('float32') / 255将数据分成训练集和测试集 train_ds = tf.data.Dataset.from_tensor_slices((x_train, y_train)).shuffle(10000).batch(32) test_ds = tf.data.Dataset.from_tensor_slices((x_test, y_test)).batch(32)定义模型 model = tf.keras.Sequential([tf.keras.layers.Flatten(input_shape=(28, 28)),tf.keras.layers.Dense(128, activation='relu'),tf.keras.layers.Dropout(0.2),tf.keras.layers.Dense(10, activation='softmax') ])定义损失函数 loss_fn = tf.keras.losses.SparseCategoricalCrossentropy(from_logits=True)定义优化器 optimizer = tf.keras.optimizers.Adam()训练模型 model.compile(optimizer=optimizer, loss=loss_fn, metrics=['accuracy']) model.fit(train_ds, epochs=10)评估模型 model.evaluate(test_ds)
结论
图像分类是计算机视觉领域的一项基本任务。使用 TensorFlow 等机器学习库,我们可以轻松训练图像分类模型,以识别图像中的对象或场景。通过遵循本文中概述的步骤,您可以构建自己的图像分类模型,并将其部署到实际应用中。
© 版权声明
文章版权归作者所有,未经允许请勿转载。
相关文章

暂无评论...
神马AI导航-国内外AI工具集导航大全是一站式AI工具箱导航平台,收录了全球数百款优质AI工具,涵盖了聊天、绘画、设计、音频、视频等各类AI应用领域。无论是卖家、设计师、开发者,还是普通用户,都能轻松在这里找到适合的AI工具,满足不同创作需求。