
👇复制口令打开淘宝免单奶茶和25红包👇
¥XT7U4sdjF9I¥/ HU7405
强化学习 (RL) 是一种机器学习范式,它使代理能够在环境中采取行动以最大化累积奖励。它在许多领域有着广泛的应用,例如机器人、游戏和金融。ReinforcementLearningBaselines 是一个开源项目,它为各种 RL 算法提供了基准实现。它由 OpenAI 维护,并旨在帮助研究人员和从业者轻松探索和比较不同的 RL 算法。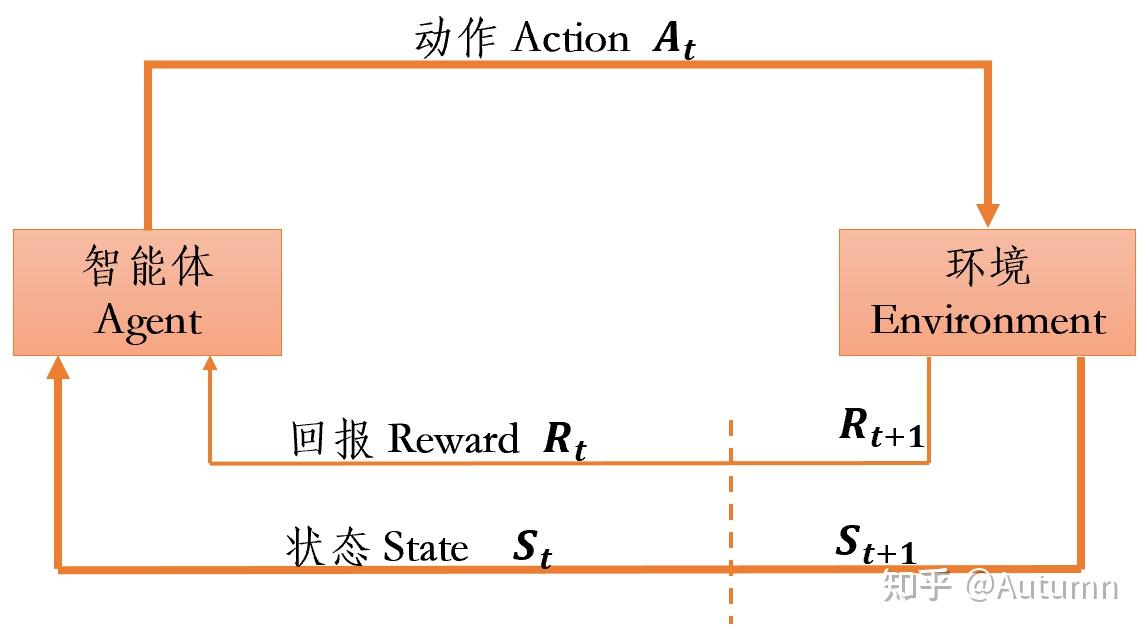
从入门到精通的学习之旅
本指南将引导你利用 ReinforcementLearningBaselines 项目踏上从入门到精通 RL 的学习之旅。
第 1 步:安装和设置
克隆 ReinforcementLearningBaselines 存储库:`git clone https://github.com/openai/baselines`创建虚拟环境并安装必要的依赖项:`pip install -r requirements.txt`
第 2 步:了解环境和动作空间
RL 算法需要交互的环境。ReinforcementLearningBaselines 提供了多种内置环境,例如网格世界和 Atari 游戏。你可以通过 gym 库访问环境:`import gym; env = gym.make(‘CartPole-v1’)`动作空间:动作空间定义了代理可以采取的可能动作的集合。对于 CartPole-v1 环境,它是一个离散空间,其中代理可以向左或向右移动。
第 3 步:实现 RL 算法
ReinforcementLearningBaselines 提供了各种 RL 算法的实现,例如:Q 学习:一种无模型算法,它通过更新状态-动作值函数来学习最优策略。在 ReinforcementLearningBaselines 中,它可以在 `baselines.deepq` 模块中找到。策略梯度:一种带梯度的算法,它通过直接优化策略的参数来学习最优策略。在 ReinforcementLearningBaselines 中,它可以在 `baselines.ppo` 模块中找到。
第 4 步:训练和评估模型
一旦你选择了算法,就可以训练模型:训练:`model = learn(env, num_timesteps=1e6)`评估:`mean_reward = evaluate(env, model, num_episodes=10)`
第 5 步:超参数调整
超参数调整对于优化 RL 算法的性能至关重要。ReinforcementLearningBaselines 提供了超参数优化工具,可以帮助你自动探索超参数空间。
第 6 步:将模型部署到实际世界
训练模型后,你可以将其部署到实际世界中。ReinforcementLearningBaselines 提供了工具,可以帮助你将模型导出为可部署格式。
其他资源
[ReinforcementLearningBaselines 文档](https://stable-baselines3.readthedocs.io/en/master/)[编写自定义环境和动作空间](https://stable-baselines3.readthedocs.io/en/master/guide/custom_env.html)[RL 算法教程](https://spinningup.openai.com/en/latest/)
结论
使用 ReinforcementLearningBaselines 项目,你可以轻松踏上从入门到精通强化学习的学习之旅。该项目提供了广泛的算法、环境和实用工具,可以帮助你快速启动并运行 RL 实验。通过遵循本文中概述的步骤,你可以构建强大的 RL agent,并在各种应用中解决复杂问题。
相关文章
